Licheng Yu

My name is Licheng Yu (虞立成). I completed my PhD in Computer Science from University of North Carolina at Chapel Hill in 2019 May. My advisor is Tamara L. Berg. I also work closely with Mohit Bansal during my PhD study. My research interest lies in computer vision and natural language processing.
I completed my Master's degrees from both Georgia Tech and Shanghai Jiaotong University in 2014. I received my Bachelor's degree from Shanghai Jiao Tong University.
Email: lichengyu [at] fb.com
Address: 1 Hacker Way, Menlo Park, CA 94025
More info: [Resume], [Google Scholar], [LinkedIn], [GitHub].
Highlights
- As always: Academic Countdown
- 2025.03: 4 papers accepted by CVPR 2025.
- 2024.09: Llama3.2 Multimodal 11B+90B released.
- 2024.02: 5 papers accepted by CVPR 2024.
- 2023.02: 3 papers accepted by CVPR 2023 and 1 paper accepted by ICLR 2023.
- 2022.07: 1 paper accepted by KDD 2022 (Talk) and 2 papers accepted by ECCV 2022.
- 2020.06: We are Winner of VQA 2020 Challenge.
- 2020.06: Organizer of LVVU 2020.
- 2020.01: TVR dataset for Large-Scale Multi-Modal TV Retrieval and Captioning released.
- 2018.08: Super cool TVQA dataset released.
- 2018.02: Referring Expression Demo online now (in CVPR2018).
- 2017.03: CVPR 2017 (spotlight presentation 8.0%). Talk is here.
- 2016.07: ECCV 2016 (spotlight presentation 4.7%). Talk is here.
- 2016.04: RefCOCO and RefCOCO+ dataset released: Referring Expression Dataset
- 2015.08: Visual Madlibs dataset released.
Work Experience
|
|
2025.07—Present: |
Senior Research Scientist Manager |

|
2019.06—2020.03: |
Researcher |
| Graduated | ||

|
2014.08—2019.05: |
Research Assistant |
|
|
2018.05—2018.08: |
Research Intern |

|
2017.05—2017.08: |
Research Intern |
|
2016.05—2016.08: |
Research Intern |

|
2011.09—2014.04:
|
Research Assistant
|
Projects & Publications
|
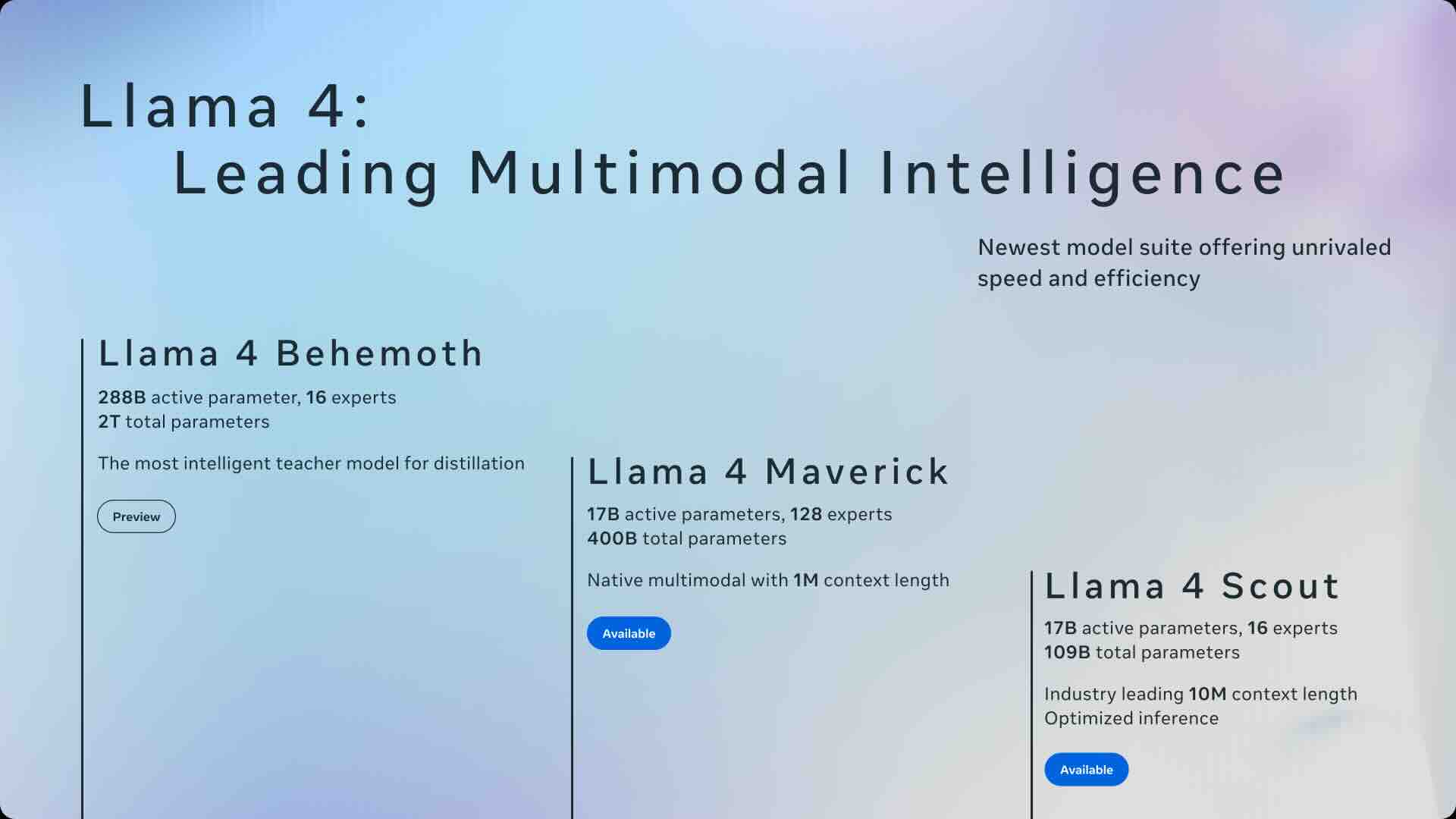
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
Llama team
[Blog]
(Led 17Bx128 and 17Bx16's text+image reinforcement learning Stage)
|
|
|
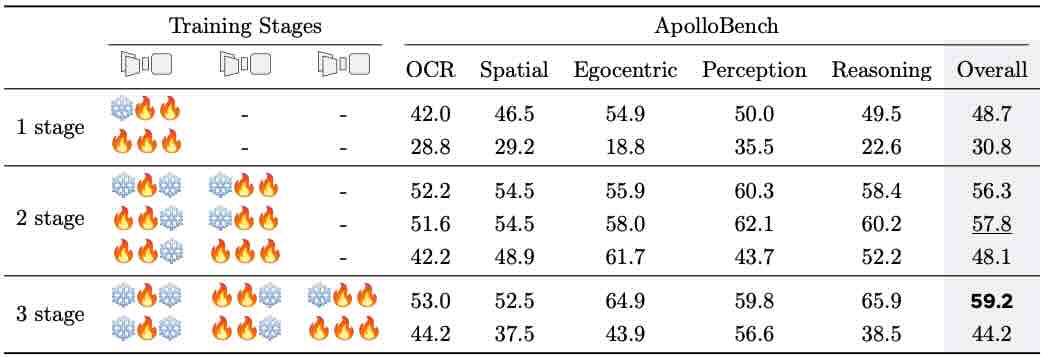
|
|
|
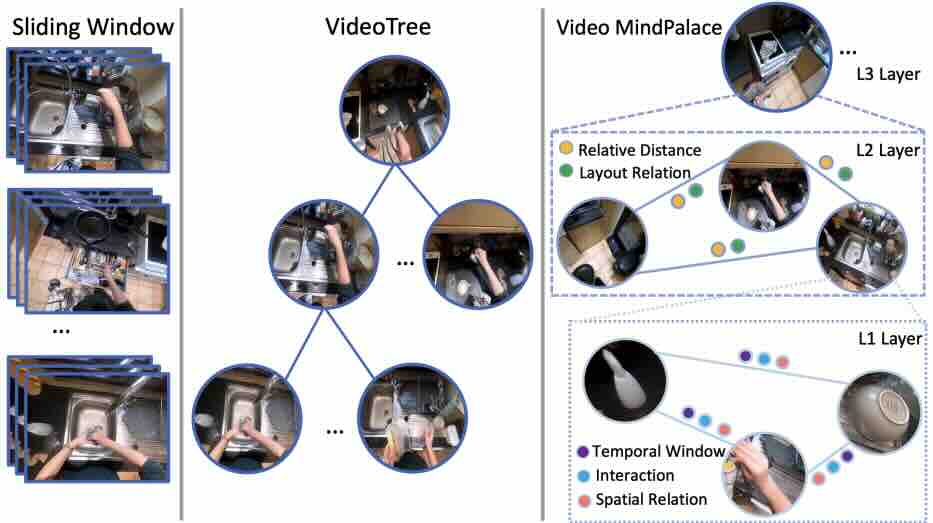
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
CVPR 2025
Zeiyi Huang, Yuyang Ji, Xiaofang Wang, Nikhil Mehta, Tong Xiao, Donghyun Lee, Sigmund Vanvalkenburgh, Shengxin Zha, Bolin Lai, Licheng Yu, Ning Zhang, Yong Jae Lee, Miao Liu
[Paper]
|

|
|

|
The Llama 3 Herd of Models
arXiv:2407.21783v2
Llama team
(Led Llama3.2 Multimodal 11B/90B Pre-training + 11B Post-training)
|

|
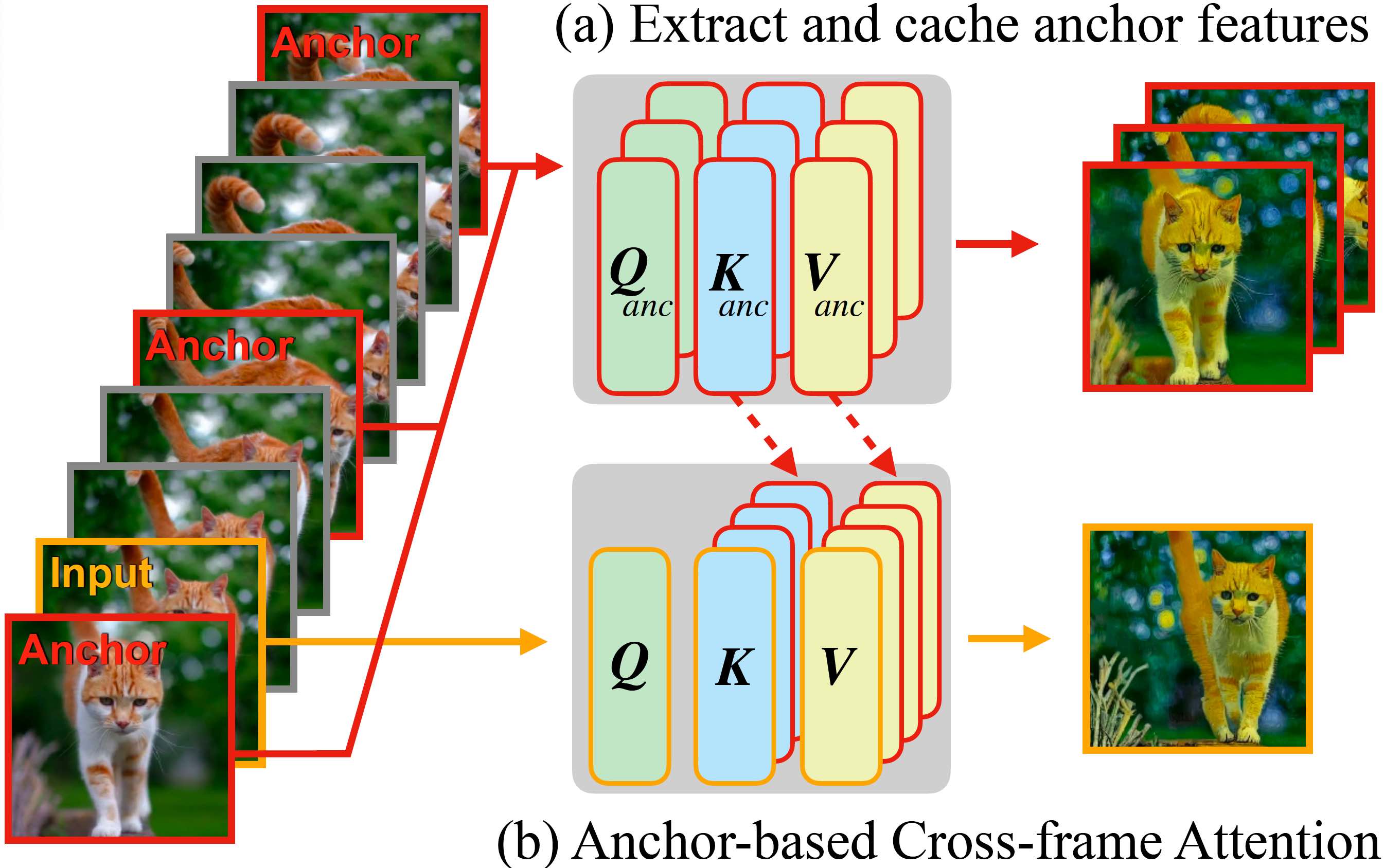
Animated Stickers: Bringing Stickers to Life with Video Diffusion
arXiv:2402.06088
David Yan, Winnie Zhang, Luxin Zhang, Anmol Kalia, Dingkang Wang, Ankit Ramchandani, Miao Liu, Albert Pumarola, Edgar Schoenfeld, Elliot Blanchard, Krishna Narni, Yaqiao Luo, Lawrence Chen, Guan Pang, Ali Thabet, Peter Vajda, Amy Bearman, Licheng Yu
[Paper]
|

|
|

|
|

|
|
|
|

|
|

|
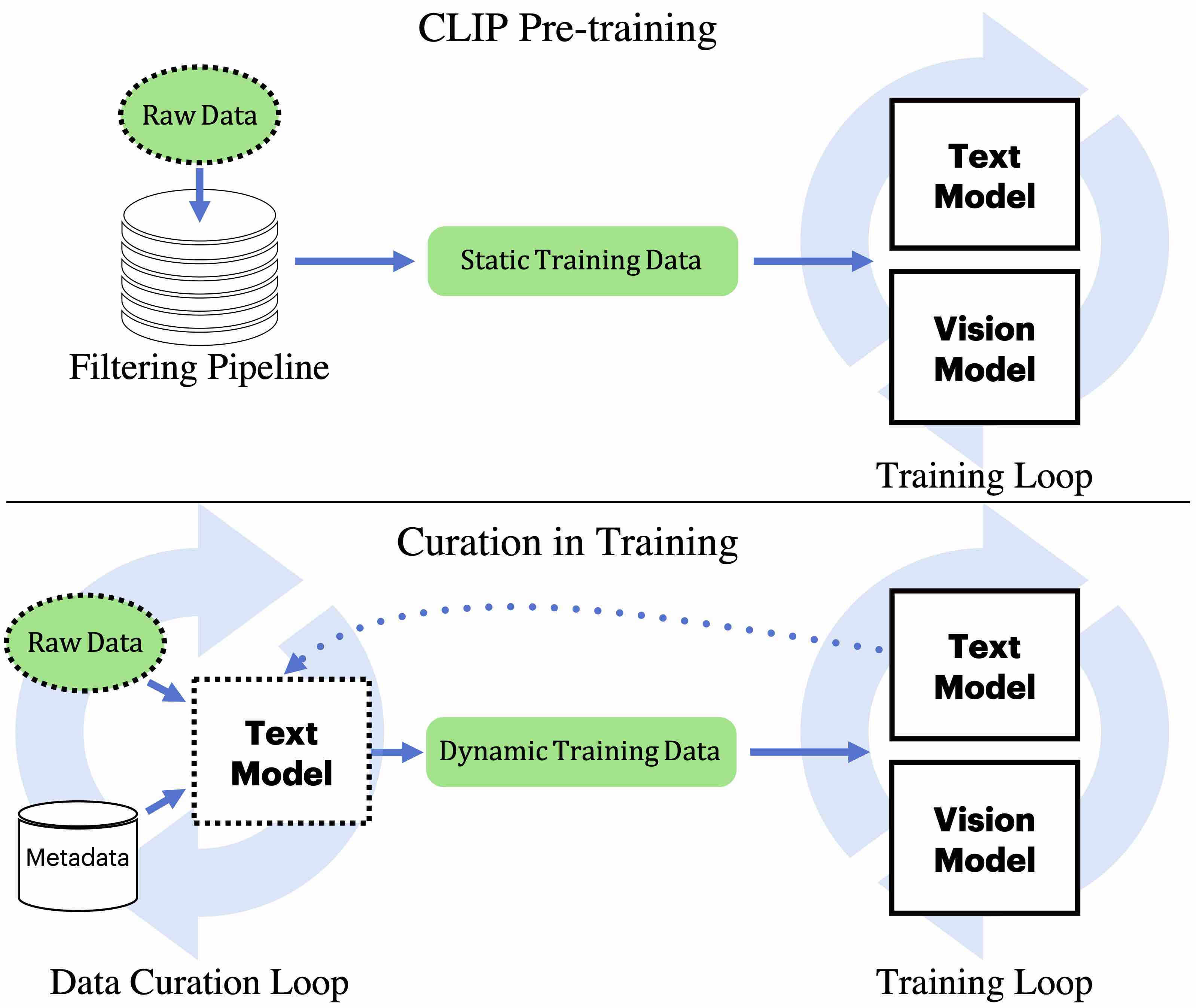
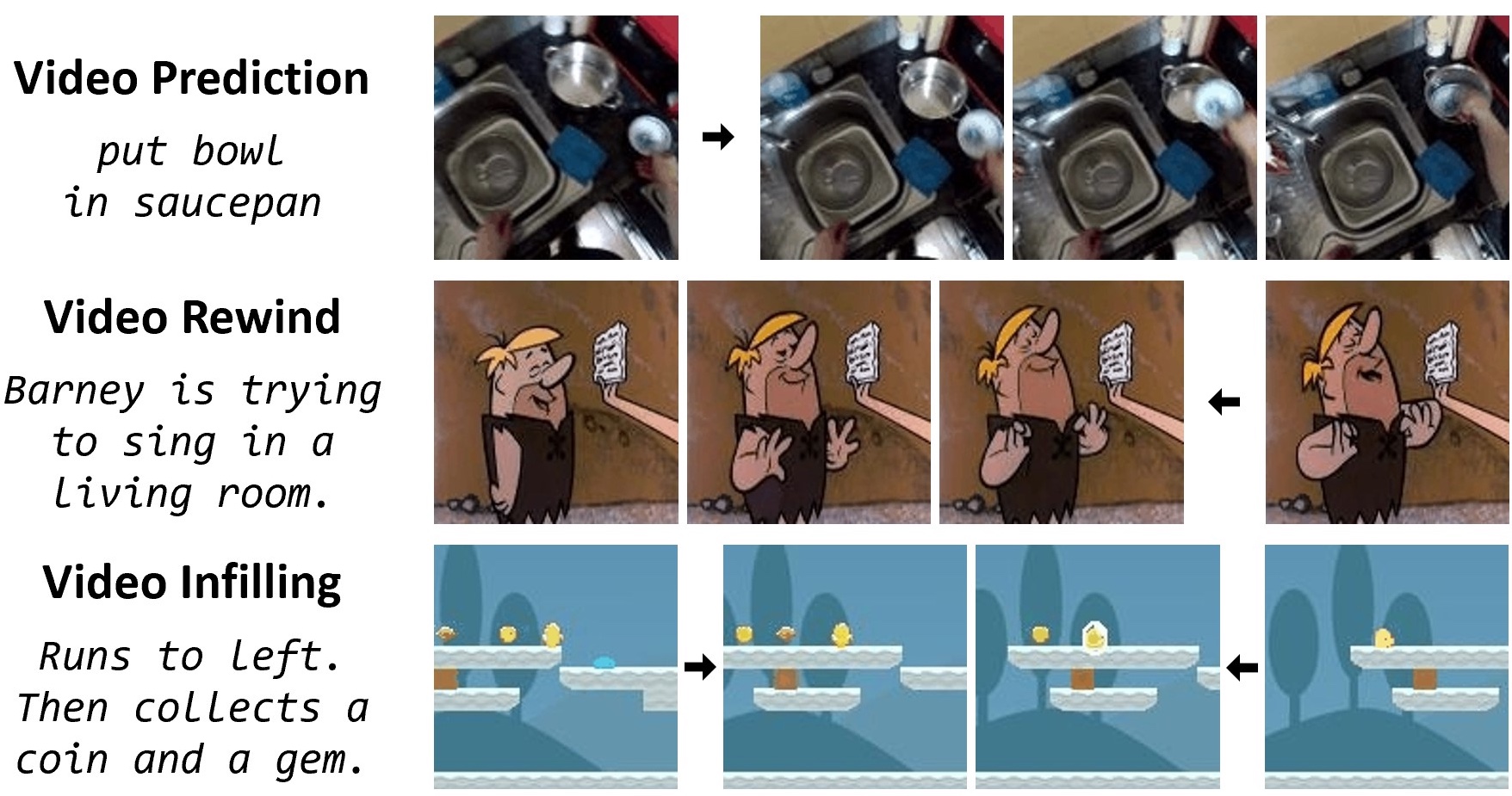
Text-to-Sticker: Style Tailoring Latent Diffusion Models for Human Expression
arXiv:2311.10794
Animesh Sinha, Bo Sun, Anmol Kalia, Arantxa Casanova, Elliot Blanchard, David Yan, Winnie Zhang, Tony Nelli, Jiahui Chen, Hardik Shah, Licheng Yu, Mitesh Kumar Singh, Ankit Ramchandani, Maziar Sanjabi, Sonal Gupta, Amy Bearman, Dhruv Mahajan
[Paper]
|
|
|
|
|
|
|
|
|
|
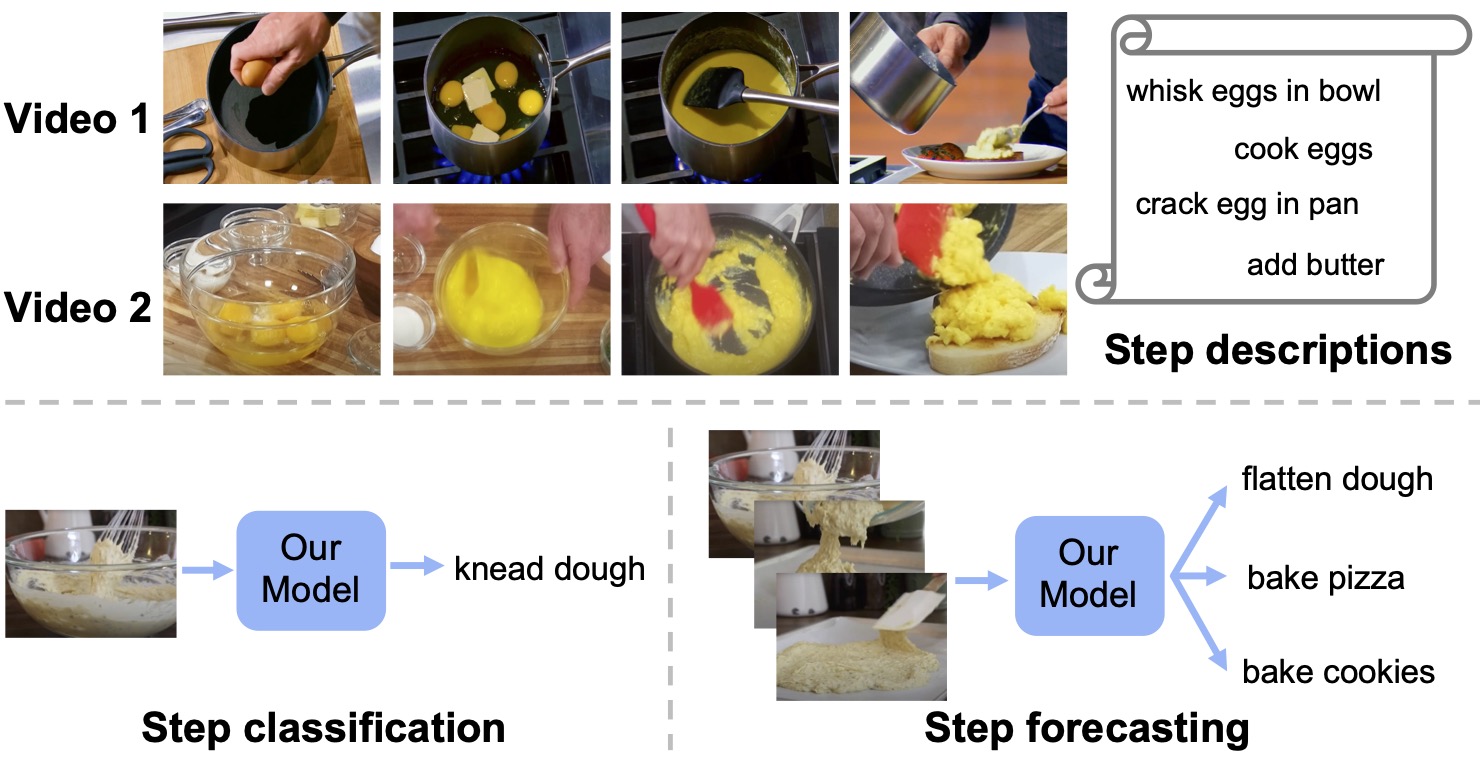
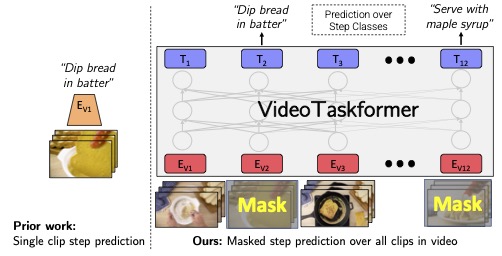
Learning and Verification of Task Structure in Instructional Videos
arXiv:2303.13519
Medhini Narasimhan, Licheng Yu, Sean Bell, Ning Zhang, Trevor Darrell
|

|
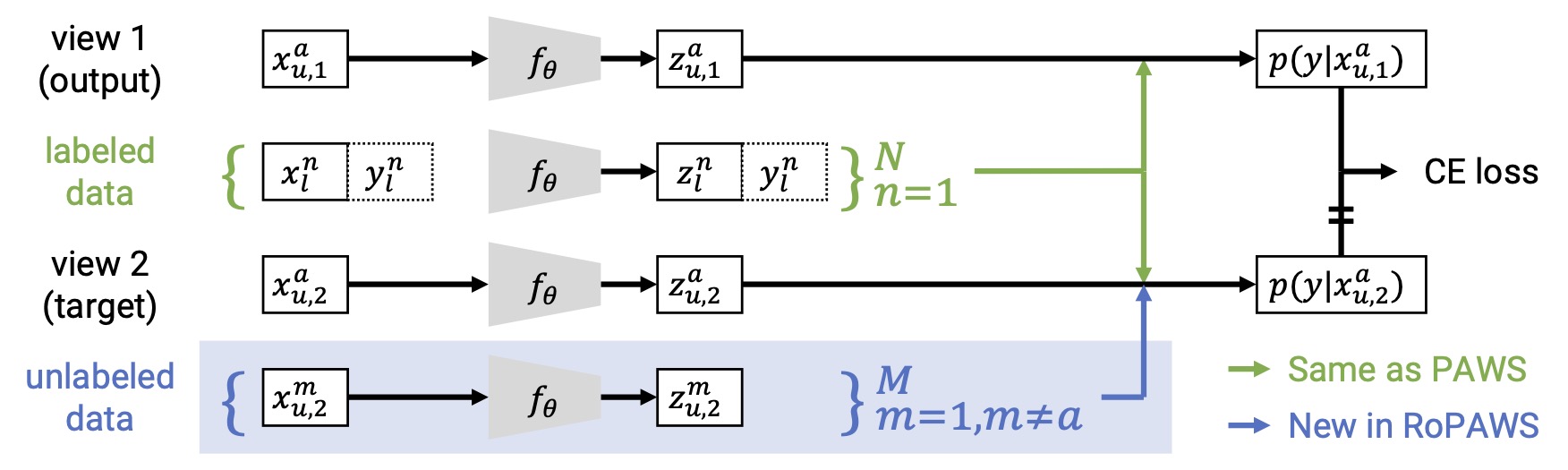
AMELI: Enhancing Multimodal Entity Linking with Fine-Grained Attributes
arXiv:2305.14725
Barry Menglong Yao, Yu Chen, Qifan Wang, Sijia Wang, Minqian Liu, Zhiyang Xu, Licheng Yu, Lifu Huang
[Paper]
|
|
|
|
|

|
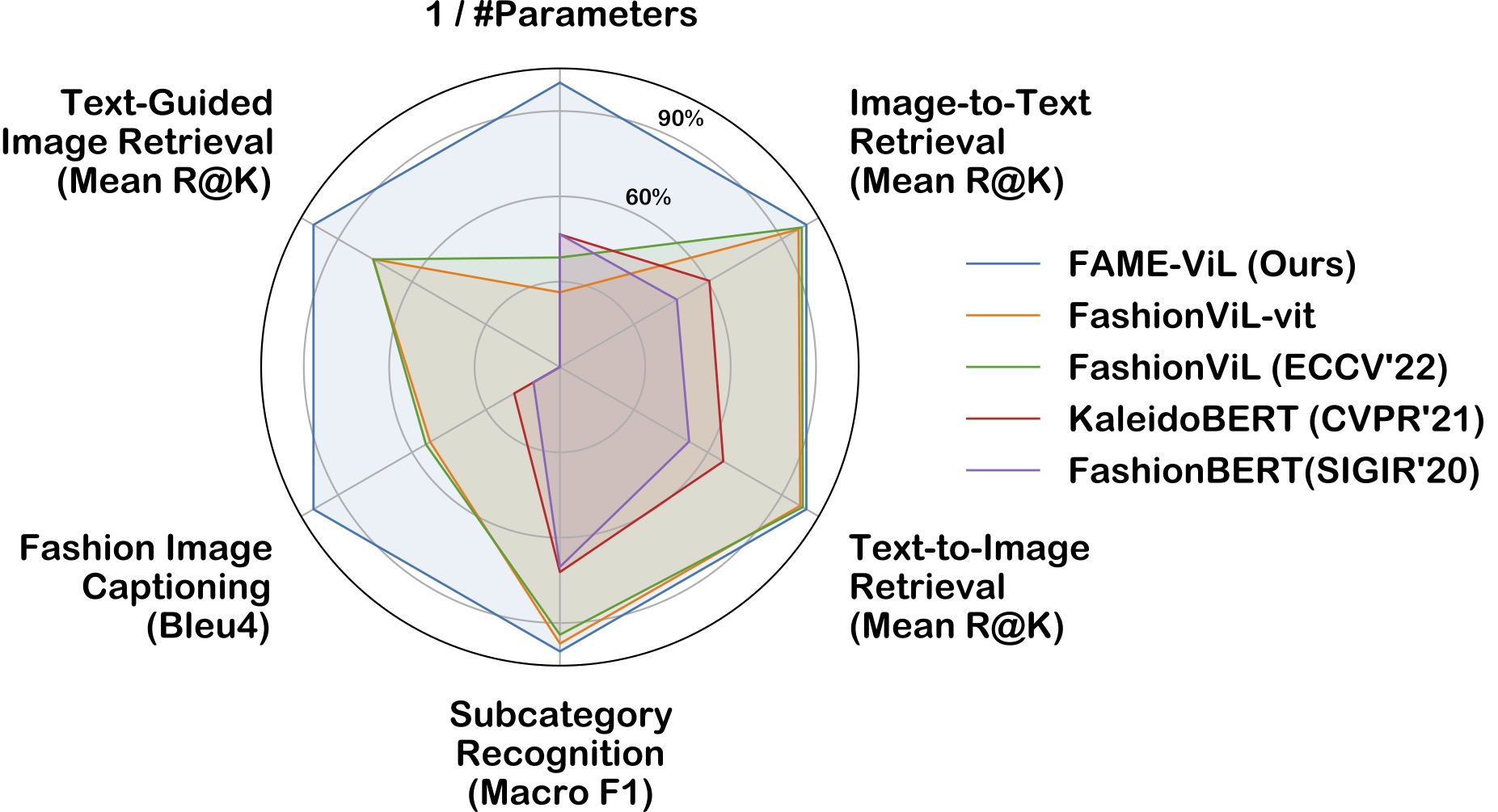
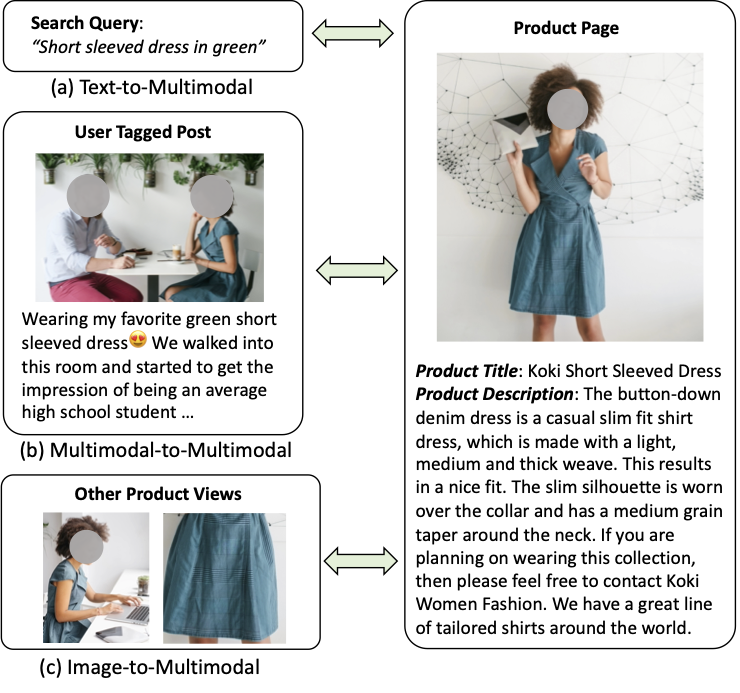
FaD-VLP: Fashion Vision-and-Language Pre-training towards Unified Retrieval and Captioning
EMNLP 2022
Suvir Mirchandani, Licheng Yu, Mengjiao Wang, Animesh Sinha, Wenwen Jiang, Tao Xiang, Ning Zhang
[Paper]
|
|
|
|
|
|
|
|
|
|
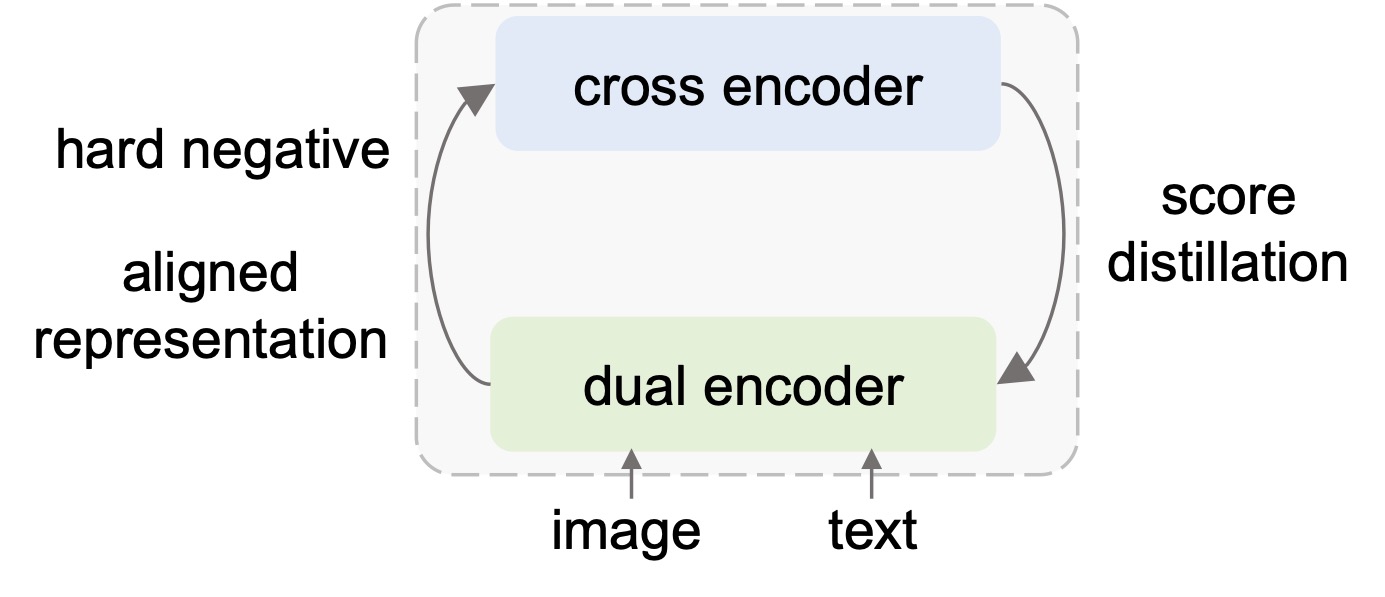
LOOPITR: Combining Dual and Cross Encoder Architectures for Image-Text Retrieval
arxiv:2203.05465v1
Jie Lei, Xinlei Chen, Ning Zhang, Mengjiao Wang, Mohit Bansal, Tamara L. Berg, Licheng Yu
[Paper]
|
|
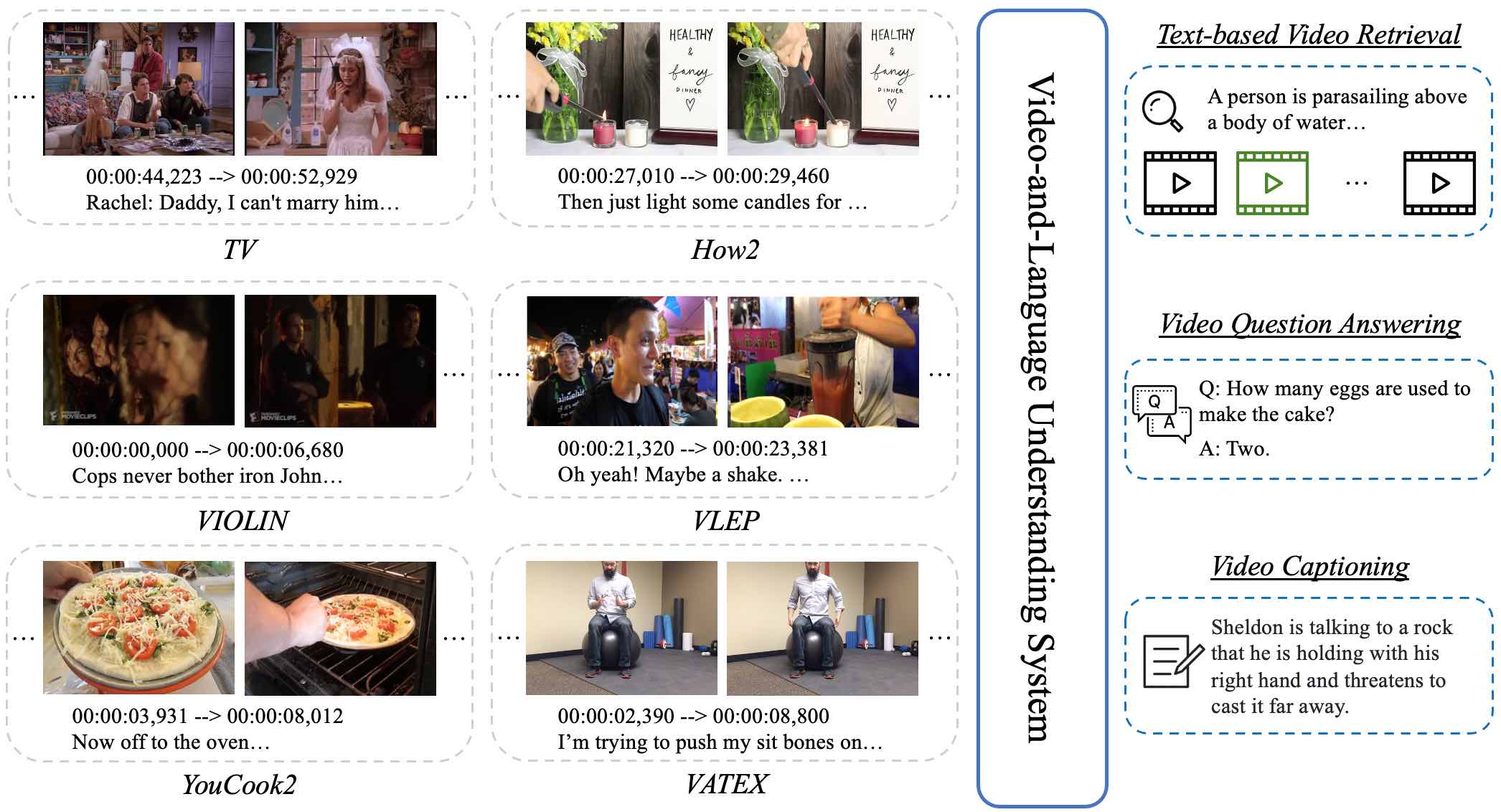
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
NeurIPS 2021
Linjie Li, Jie Lei, Zhe Gan, Licheng Yu, Yen-Chun Chen, Rohit Pillai, Yu Cheng, Luowei Zhou, Xin Eric Wang, William Yang Wang, Tamara L. Berg, Mohit Bansal, Jingjing Liu, Lijuan Wang, Zicheng Liu
[Paper][Leaderboard]
|

|
|

|
What is More Likely to Happen Next? Video-and-Language Future Event Prediction
EMNLP 2020
Jie Lei, Licheng Yu, Tamara L. Berg, Mohit Bansal
|
|
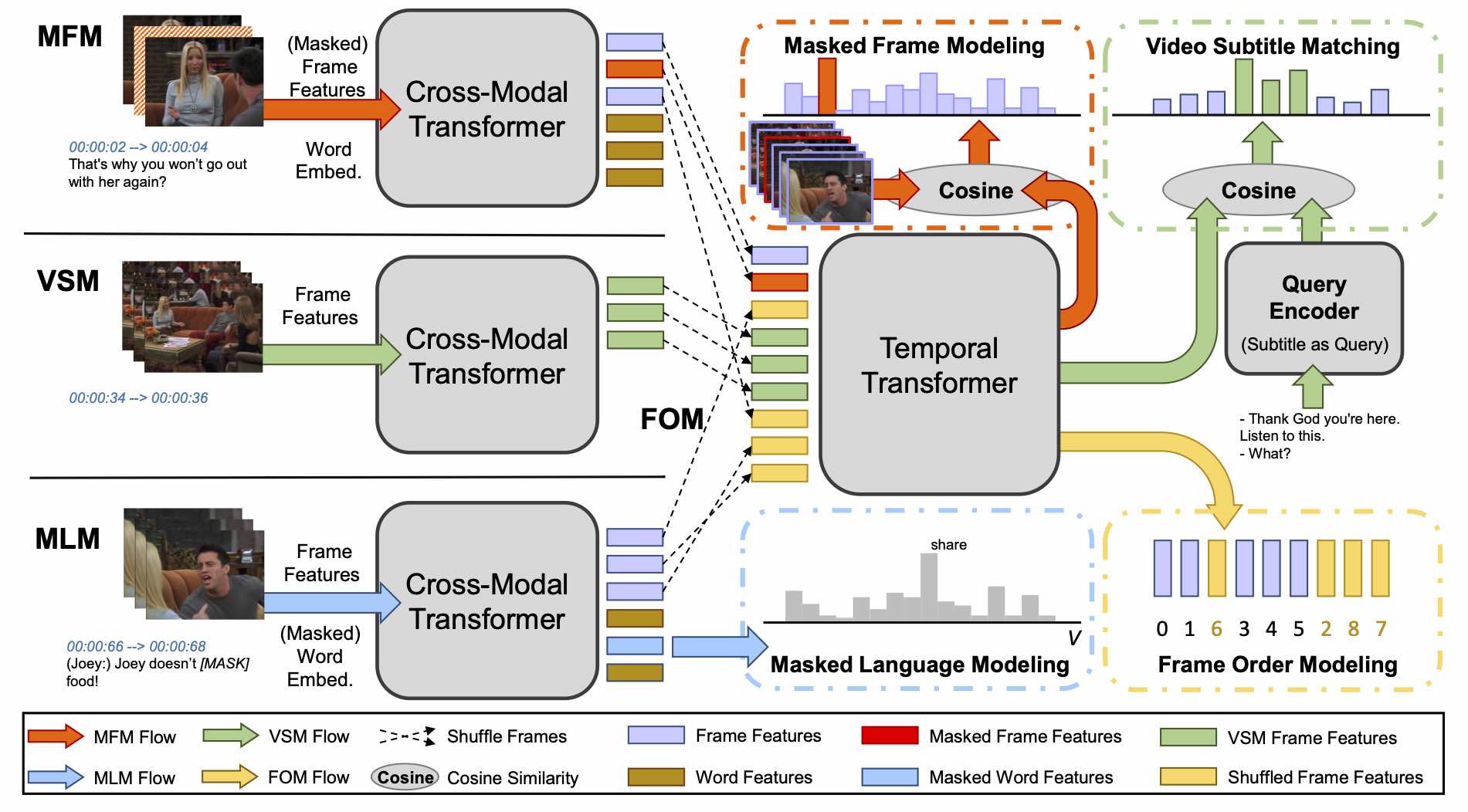
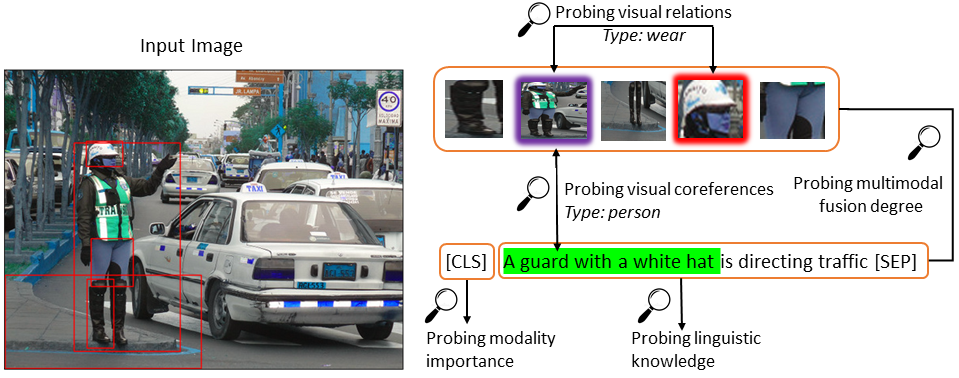
HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
EMNLP 2020
Linjie Li*, Yen-Chun Chen*, Yu Cheng, Zhe Gan, Licheng Yu, Jingjing Liu
Rank 1 on TVR Leaderboard(*First 2 authors contribute equally.) Rank 1 on TVC Leaderboard |
|
|

|
TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
ECCV 2020
Jie Lei, Licheng Yu, Tamara L. Berg, Mohit Bansal
|
|
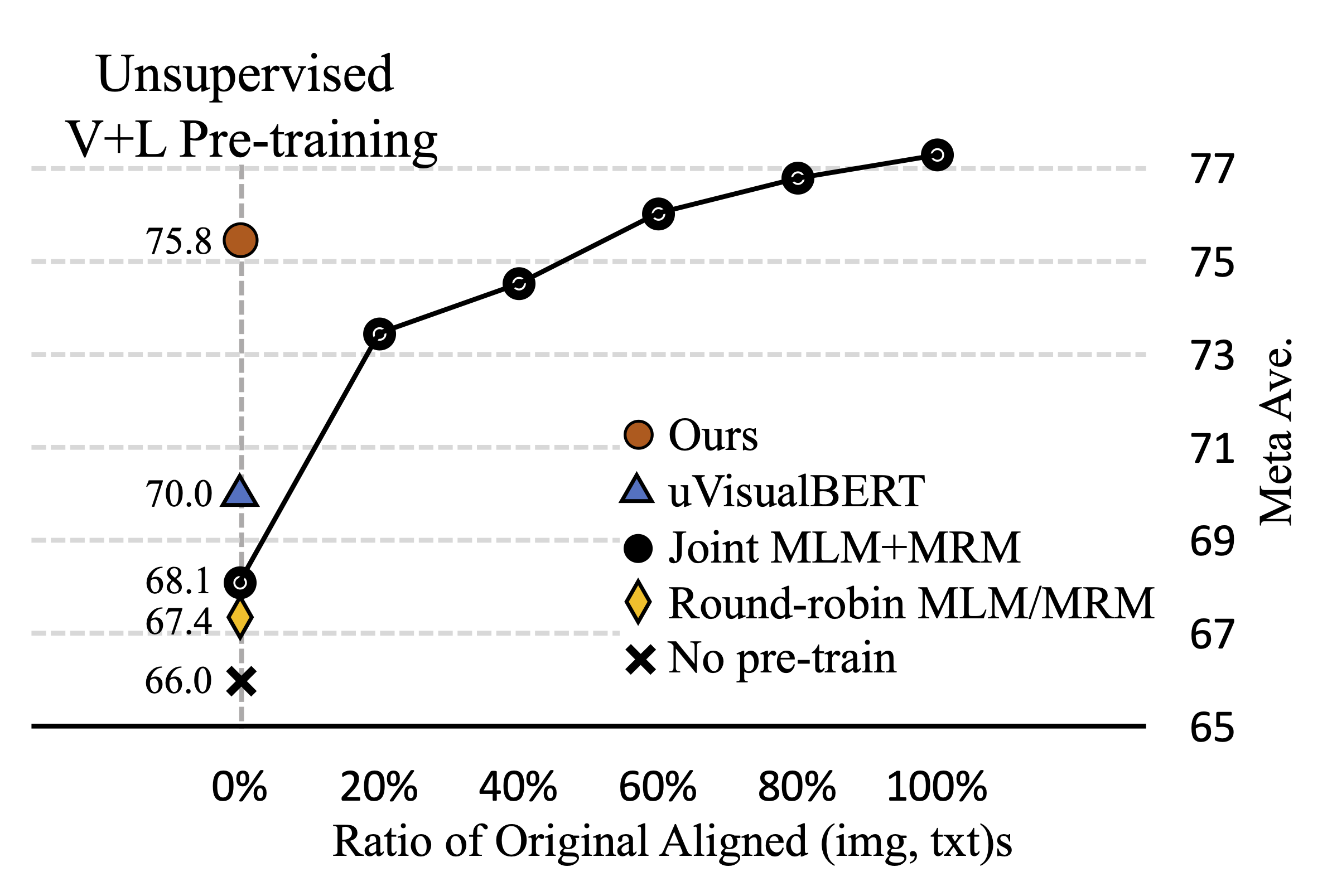
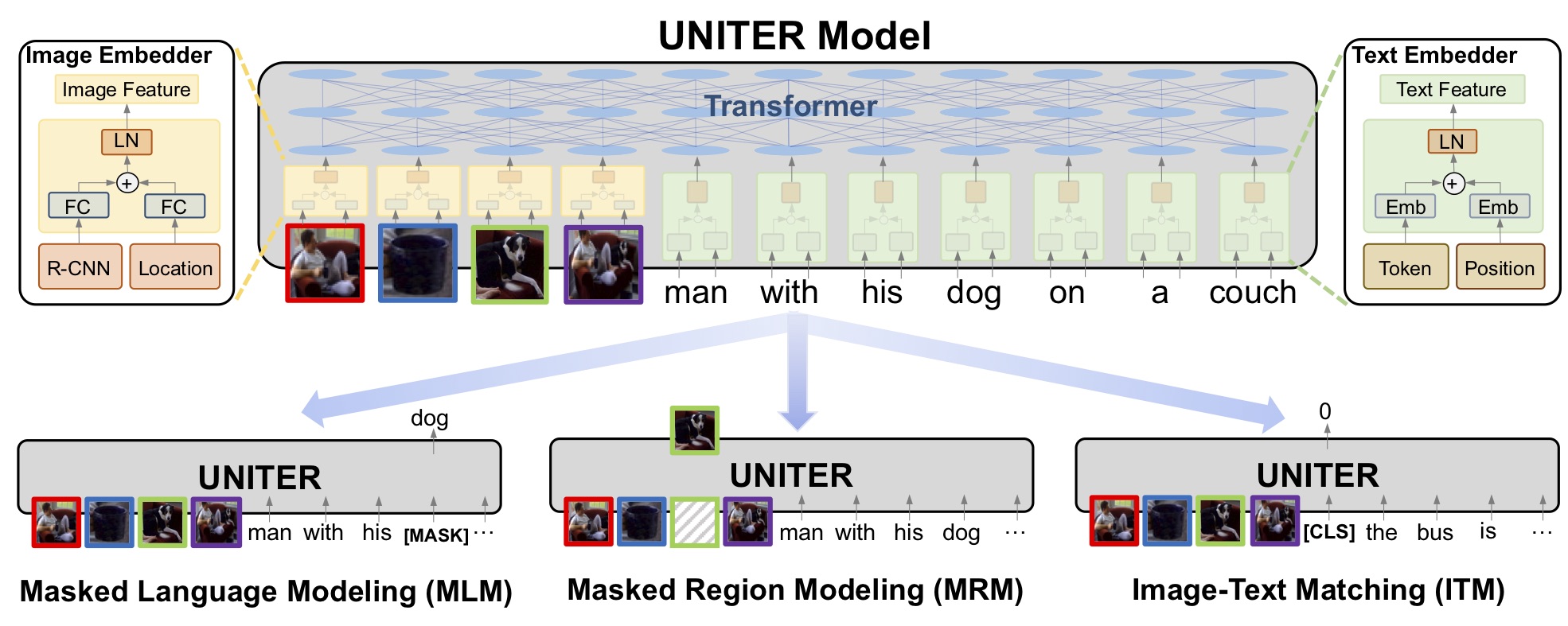
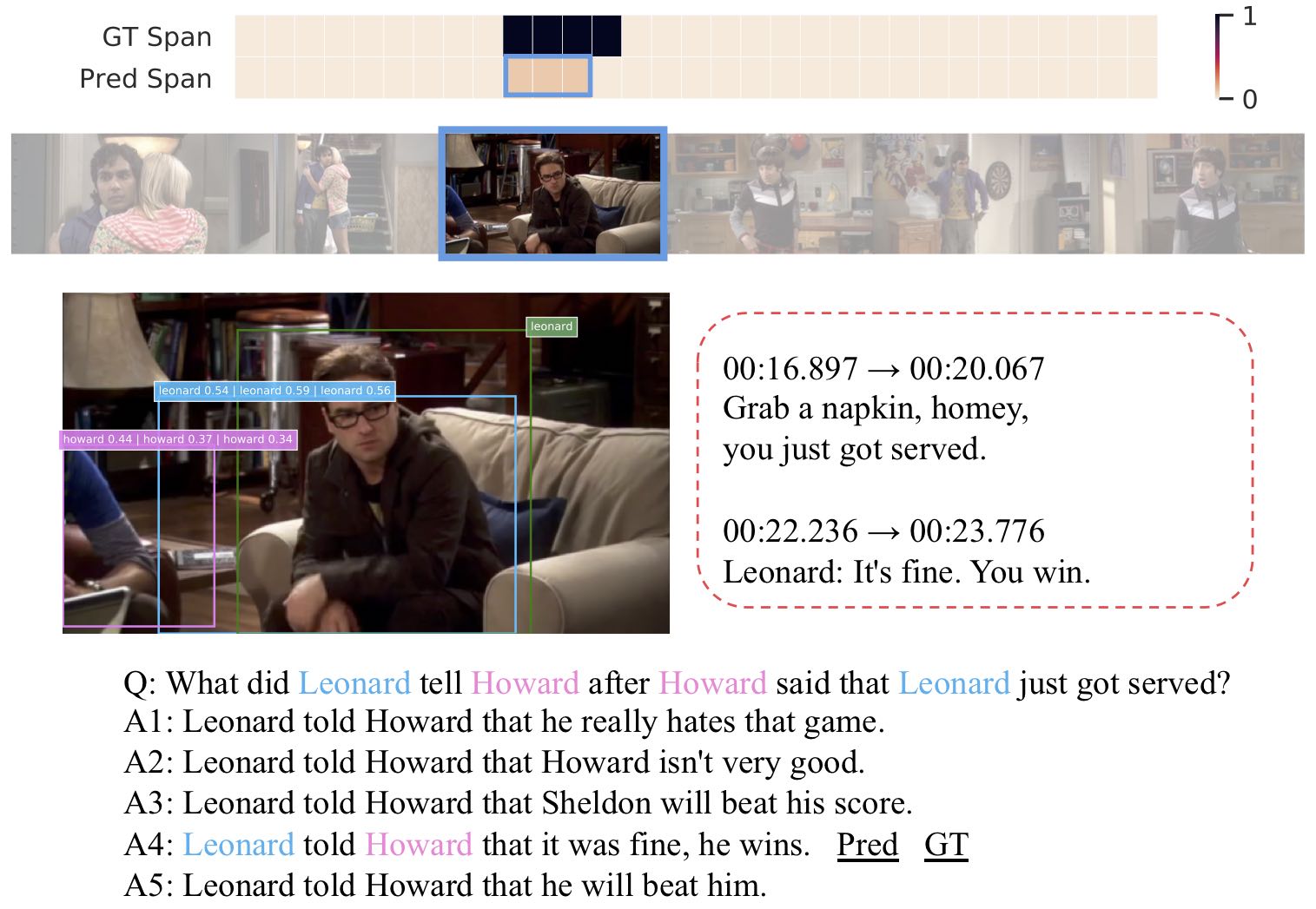
UNITER: Learning UNiversal Image-Text Representations
ECCV 2020
Yen-Chun Chen*, Linjie Li*, Licheng Yu*, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, Jingjing Liu
(*First 3 authors contribute equally.)
Achieving SOTA on 13 Vision+Language Datasets/Tasks, and
Rank 1 on VCR Leaderboard Rank 1 on NLVR2 Leaderboard |
|
|
|
|

|
|

|
|
|
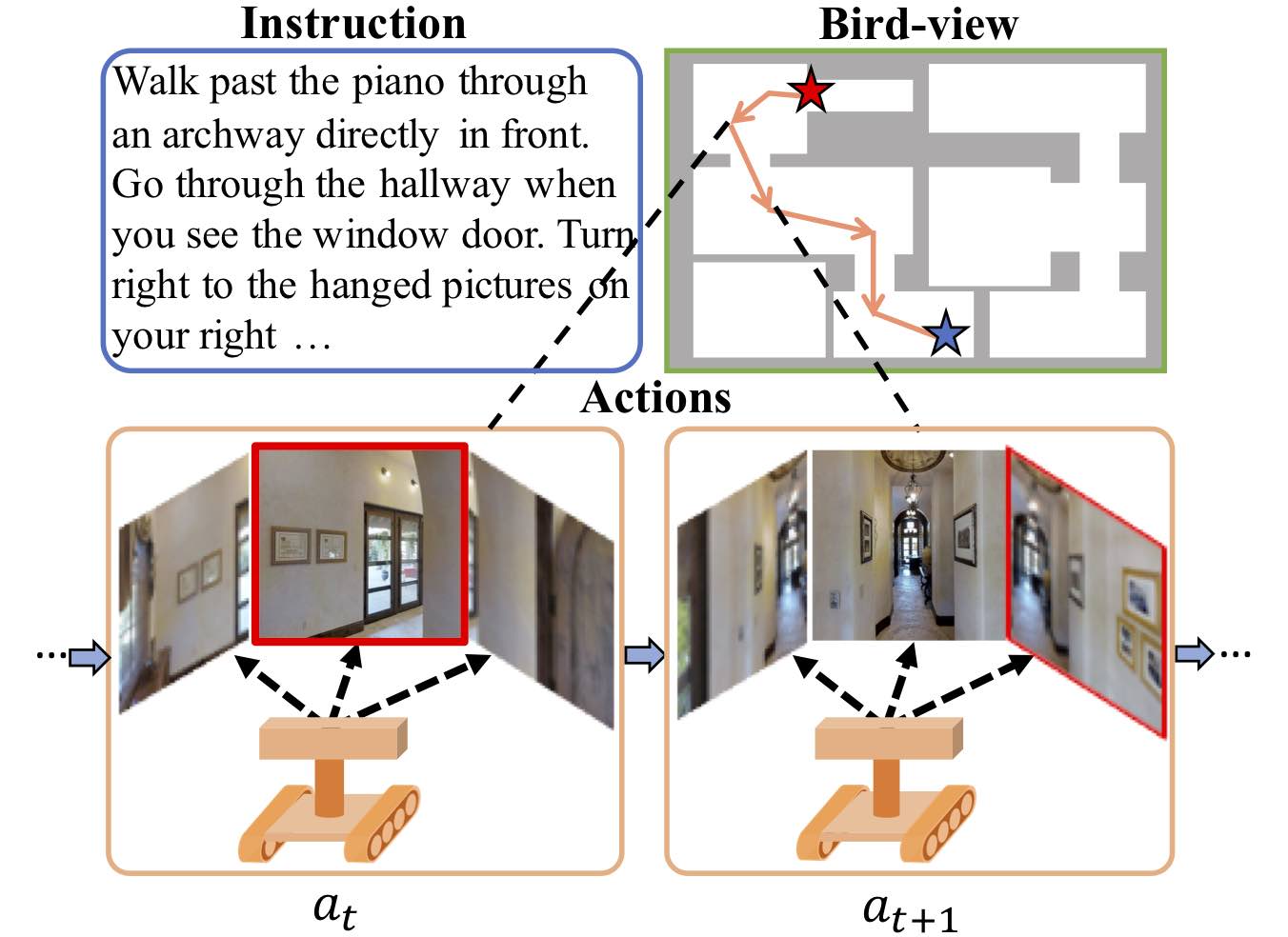
Learning to Navigate Unseen Environments: Back Translation with Environmental Dropout
NAACL 2019
Hao Tan, Licheng Yu, Mohit Bansal
|

|
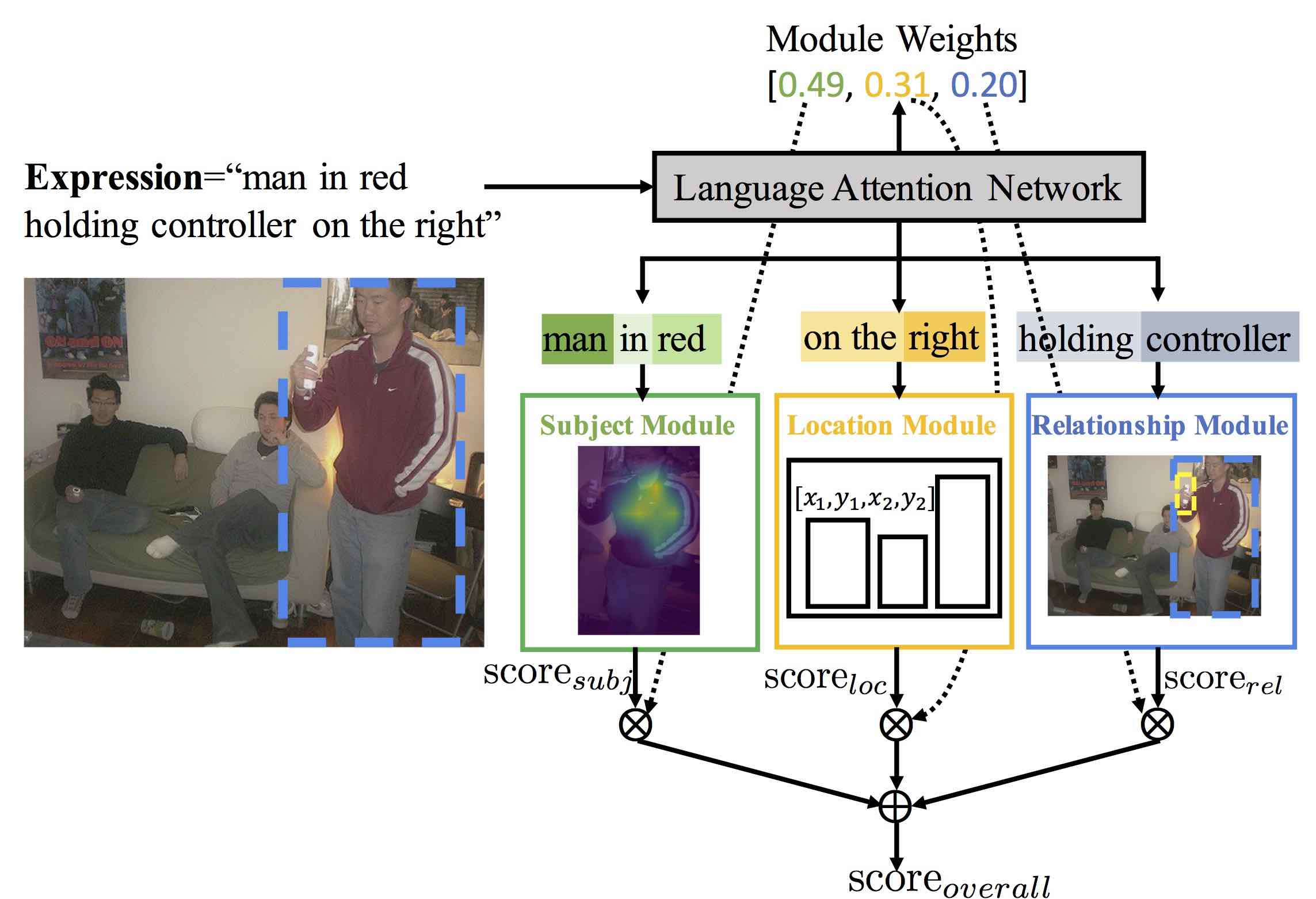
TVQA: Localized Compositional Video Question Answering
EMNLP 2018
Jie Lei, Licheng Yu, Mohit Bansal, Tamara L. Berg
|
|
|

|
From Image to Language and Back Again
Journal of Natural Language Engineering (JNLE), 2018
Anya Belz, Tamara L. Berg, Licheng Yu
[Paper]
|
|
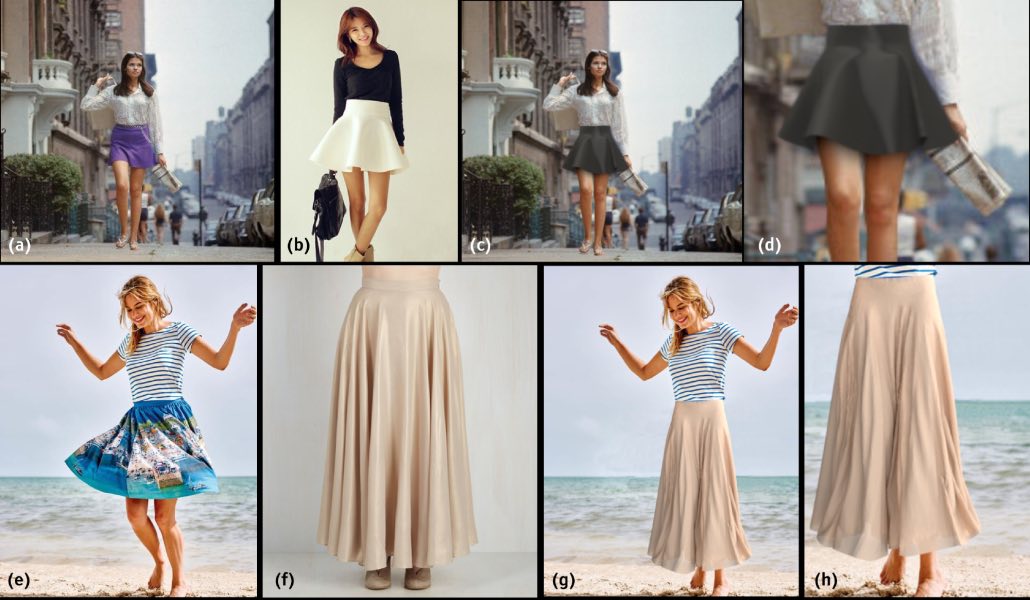
Physics-Inspired Garment Recovery from a Single-View Image
ACM Transactions on Graphics, 2018
Shan Yang, Tanya Ambert, Zherong Pan, Ke Wang, Licheng Yu, Tamara L. Berg, Ming C. Lin
|
|
A Unified Framework for Manifold Landmarking
IEEE Transactions on Signal Processing, 2018
Hongteng Xu, Licheng Yu, Mark Davenport, Hongyuan Zha
[Paper]
|
|
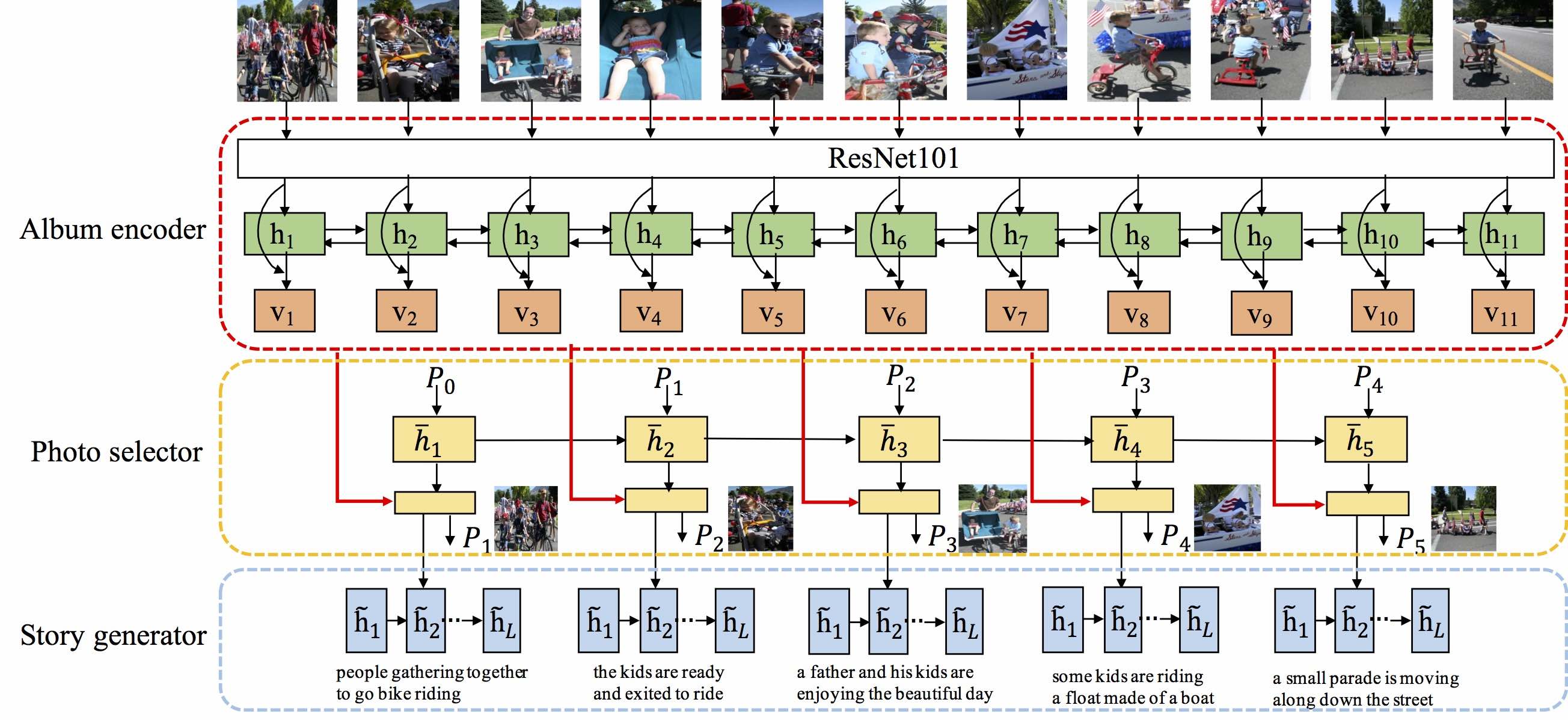
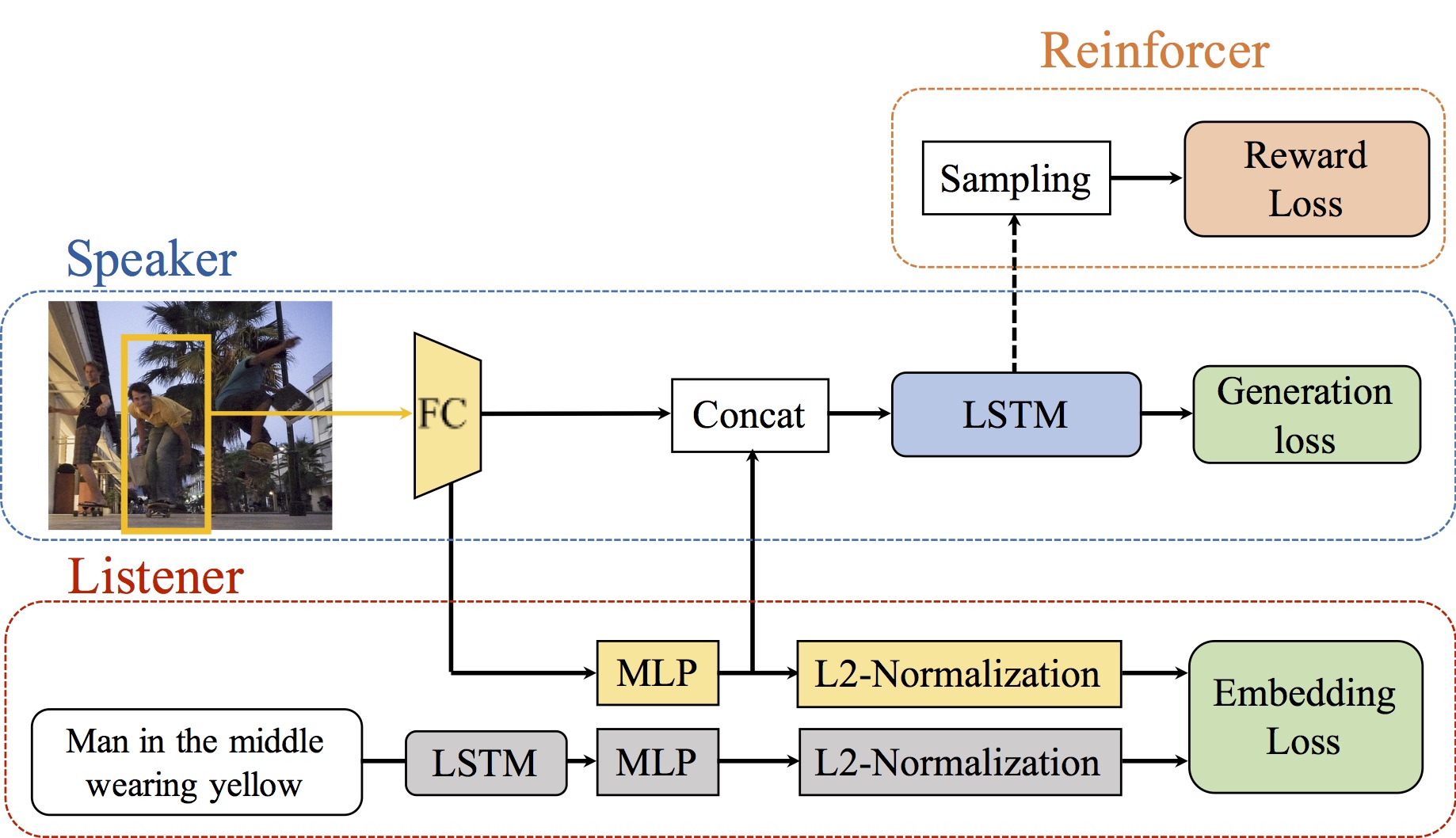
Hierarchically-Attentive RNN for Album Summarization and Storytelling
EMNLP 2017
Licheng Yu, Mohit Bansal, Tamara L. Berg
[Paper]
[Dataset API]
|
|
|
|
|

|
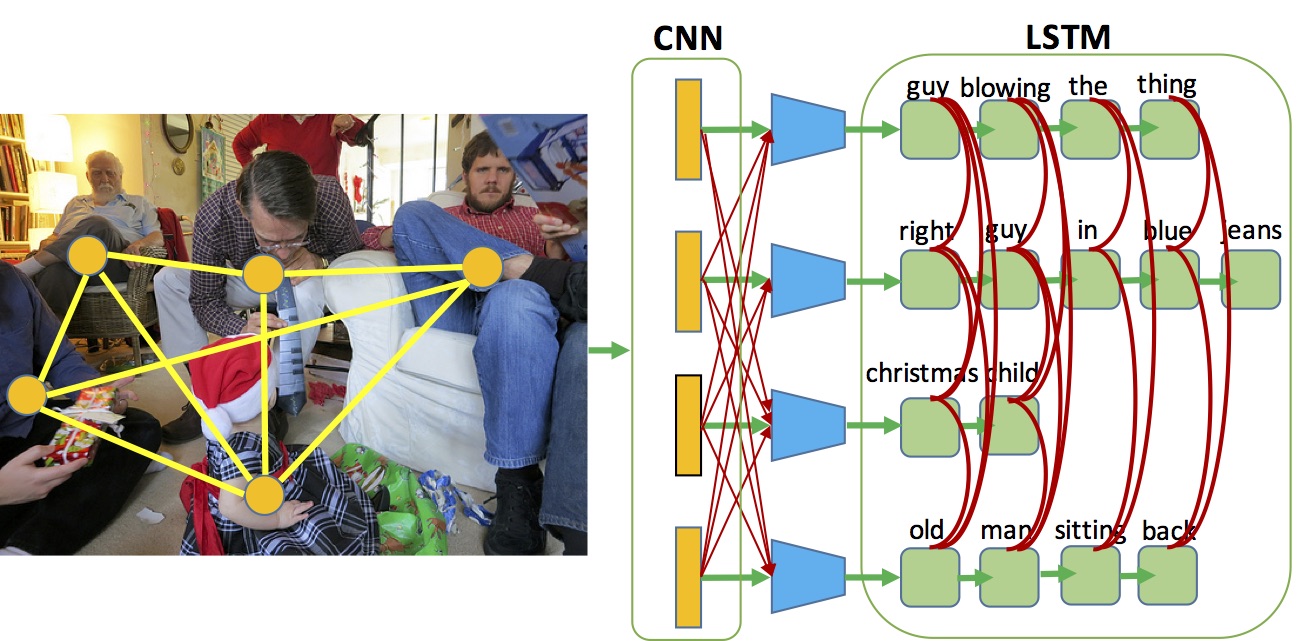
Visual Madlibs: Fill-in-the-blank Image Description and Question Answering
ICCV 2015
Licheng Yu, Eunbyung Park, Alexander C. Berg, Tamara L. Berg
|
|
|
|
|

|
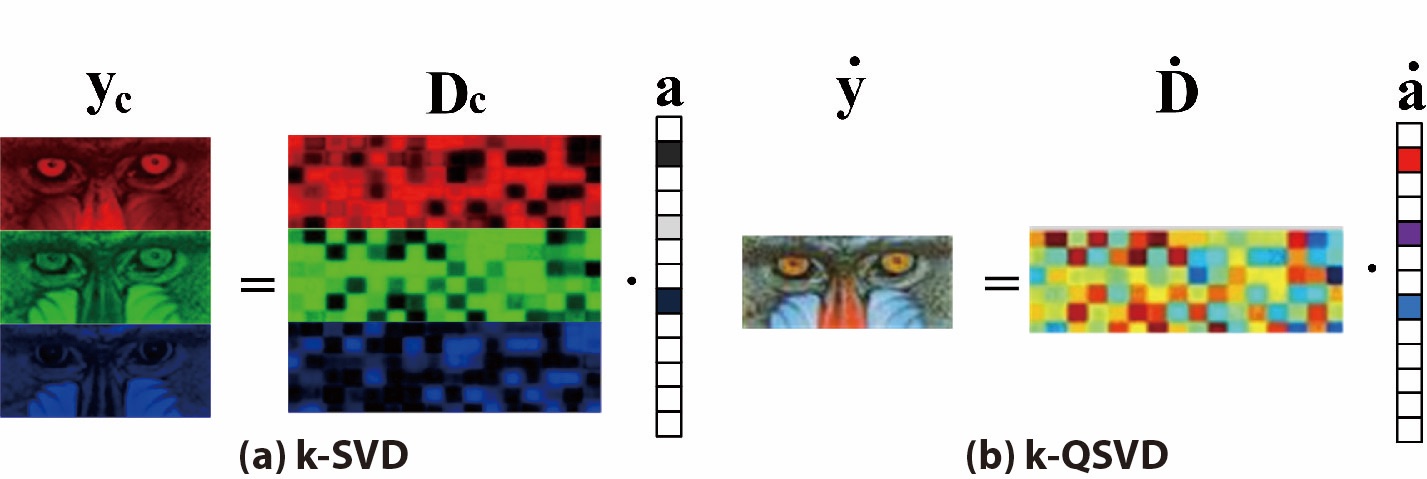
Quaternion-based Sparse Representation of Color Image
IEEE International Conference on Multimedia and Expo, ICME 2013
Licheng Yu, Yi Xu, Hongteng Xu, Hao Zhang
[Paper][Supplementary File] (Oral presentation)
|

|
Single Image Super-resolution via Phase Congruency Analysis
IEEE Visual Communications and Image Processing, VCIP 2013
Licheng Yu, Yi Xu, Bo Zhang
[Paper] (Oral presentation)
|
|
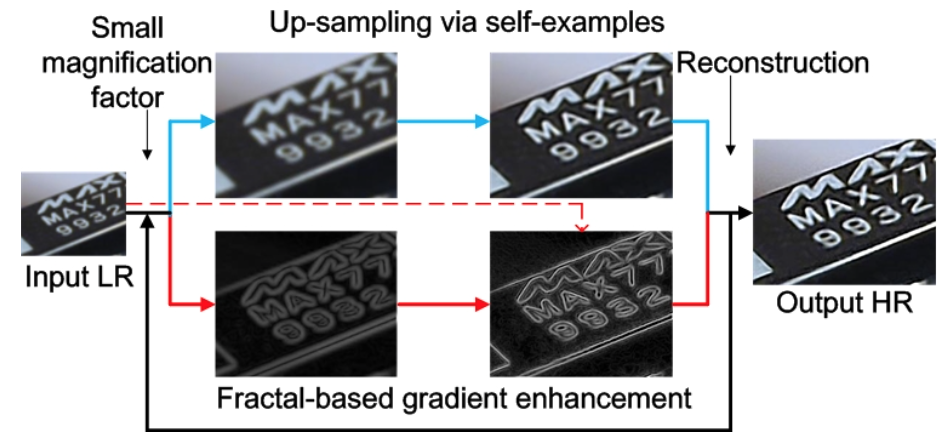
Self-Example Based Super-resolution with Fractal-based Gradient Enhancement
IEEE International Conference on Multimedia and Expo, ICME workshop 2013
Licheng Yu, Yi Xu, Hongteng Xu
[Paper]
|
|
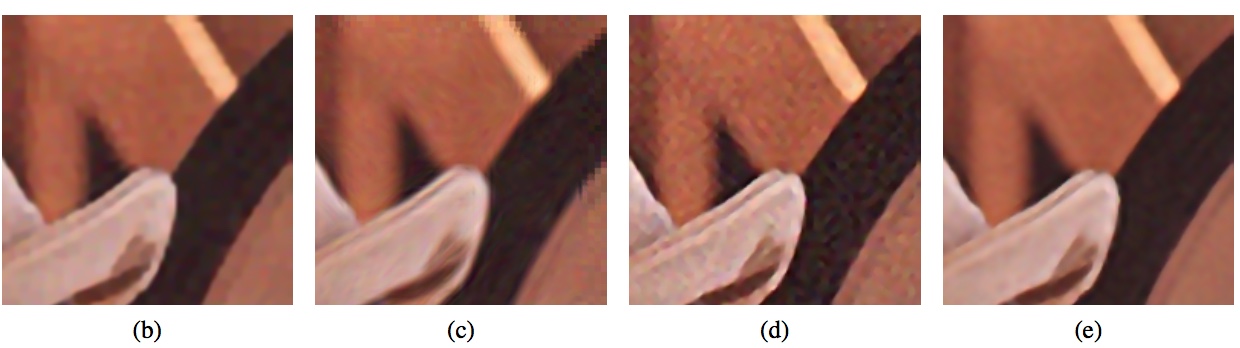
Robust Single Image Super-resolution based on Gradient Enhancement
APSIPA Annual Summit and Conference, APSIPA 2012
Licheng Yu, Yi Xu, Hongteng Xu, Xiaokang Yang
|
Miscellaneous
|
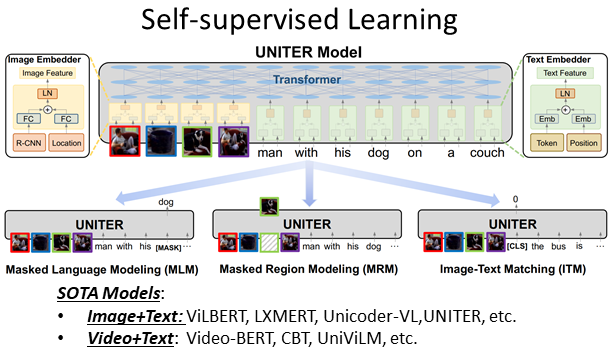
Self-supervised Learning for Vision-and-Language
Recent Advances in Vision-and-Language Research
CVPR 2020 Tutorial
Licheng Yu, Linjie Li, Yen-Chun Chen
|

|
Revisiting Grid Features for VQA
Duy-Kien Nguyen, Huaizu Jiang, Vedanuj Goswami, Licheng Yu, Xinlei Chen
Winner of VQA 2020 Challenge
|
|
|

|